Step-by-Step Guide to Enhancing AutoGPT with Pinecone Vector Database in Colab: Unlocking the Power of Long-Term Memory
A comprehensive guide to supercharge your AutoGPT with the power of Pinecone vector database, opening up new use cases and possibilities
Introduction
This article explores the integration of AutoGPT, an open-source application that demonstrates the capabilities of the GPT-4 language model, with Pinecone, a powerful vector database. By adding long-term memory to the language model using Pinecone, we can enhance the overall functionality and unlock new use cases for AutoGPT.
Before diving into the step-by-step guide, let’s take a deeper look at AutoGPT and the concept of vector databases, and understand why integrating the two can bring value to your projects.
Vector Databases Like Pinecone: Demystifying the Concept
A vector database, like Pinecone, is a specialized database designed to store, search, and manage high-dimensional vectors. These vectors, mathematical representations of data points, are widely used in machine learning, natural language processing, and recommendation systems. The strength of a vector database lies in its ability to handle large-scale data and perform efficient similarity searches, retrieving relevant information quickly and effectively.
Integrating AutoGPT with Pinecone Vector Database
Let’s walk through the steps to integrate AutoGPT with Pinecone vector database:
Step 1: Install Pinecone
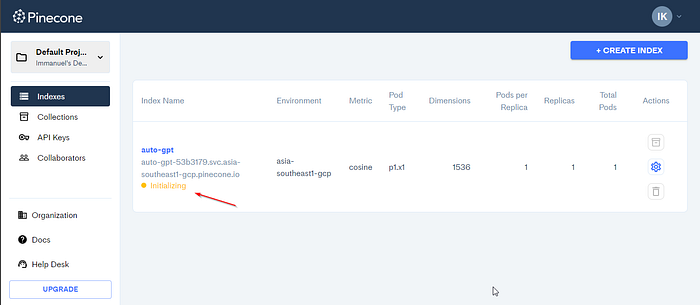
Before installing AutoGPT, let’s set up Pinecone. First, go to Pinecone.io and create an account. Then, find your API key and region under the default project in the left sidebar.

Step 2: Install AutoGPT
To install AutoGPT, run the following code:
!git clone https://github.com/Significant-Gravitas/Auto-GPT.git -b stable --single-branch
%cd Auto-GPT/
!pip install -r requirements.txt
%cd Auto-GPT/
!cp .env.template env.txtStep 3: Update env.txt with Your Keys
Update the env.txt file with your keys for OpenAI, Pinecone, and Google Custom Search.

Step 4: Set up the Environment Variables
Run the following code:
!cp env.txt .env
Step 5: Run AutoGPT
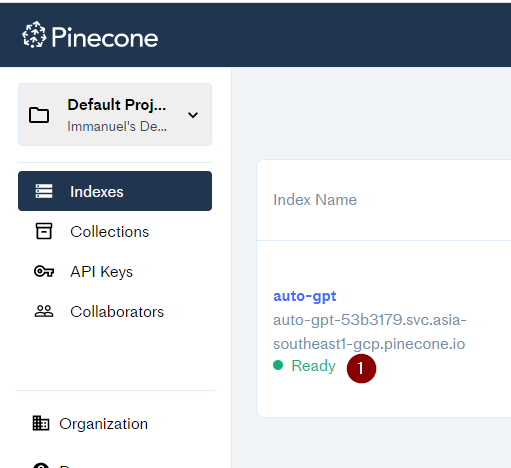
!python -m autogpt --continuousUpon running AutoGPT for the first time, it may fail due to Pinecone needing some time to warm up. Give Pinecone a few minutes to initialize, then run AutoGPT again.
Expanding AutoGPT Features and Use Cases
By integrating AutoGPT with Pinecone vector database, we can enhance its features, making it more versatile and valuable for various applications. Some examples of expanded use cases include:
- Personalized recommendations: With long-term memory, AutoGPT can store user preferences and generate personalized content, product, or service recommendations.
- Sentiment analysis: AutoGPT can analyze customer feedback over time, identifying trends and patterns that can help businesses improve customer satisfaction.
- Document summarization: AutoGPT can quickly process and summarize vast amounts of textual data, providing users with condensed, easy-to-understand information.
- Customer support: AutoGPT can access long-term memory to provide context-aware assistance to customers, improving the efficiency and effectiveness of support interactions.
- Content generation: AutoGPT can utilize long-term memory to create context-aware, original content that caters to specific user interests and needs.
Conclusion
Integrating AutoGPT with Pinecone vector database adds long-term memory to the language model, enhancing its overall functionality and opening up new use cases. By following the steps outlined in this guide, you can supercharge your AutoGPT implementation, unlocking its full potential for a wide range of applications. Embrace the power of long-term memory and witness the true capabilities of AutoGPT.
Bonus: Understanding Vector Databases: How They Work and Real-World Analogies
A vector database functions quite differently from traditional databases, which store scalar data such as strings and numbers in rows and columns. Vector databases, as the name suggests, operate on vectors and utilize specialized algorithms to optimize and query their data. Let’s break down how a vector database works, using real-world examples and analogies to make the concept more intuitive.
Vector databases employ a technique called Approximate Nearest Neighbor (ANN) search, which allows them to find the most similar vector to a given query using a similarity metric. This contrasts with traditional databases that typically search for exact matches. ANN search relies on a combination of algorithms such as hashing, quantization, or graph-based search to optimize the search process.
Imagine a library where books are organized based on their topics. To find a book on a specific topic, you don’t need to check every bookshelf. Instead, you can quickly locate the appropriate section and browse only the relevant books. Similarly, ANN algorithms help vector databases narrow down the search space, allowing them to retrieve relevant vectors more efficiently.
A typical vector database pipeline consists of the following stages:
- Indexing: The vector database indexes vectors using algorithms like PQ (Product Quantization), LSH (Locality-Sensitive Hashing), or HNSW (Hierarchical Navigable Small World). This step maps the vectors to a data structure that enables faster searching. For example, indexing in a library involves categorizing books by subject, author, or title to facilitate quicker access.
- Querying: The vector database compares the indexed query vector to the indexed vectors in the dataset to find the nearest neighbors, applying a similarity metric used by that index. This is like searching for a book in the library by looking for the most relevant books within the identified section.
- Post Processing: In some cases, the vector database retrieves the final nearest neighbors from the dataset and post-processes them to return the final results. This step can include re-ranking the nearest neighbors using a different similarity measure. It’s similar to browsing through the relevant books in a library and picking the most suitable one based on additional criteria, such as publication date or author.
A key trade-off in vector databases is between accuracy and speed. More accurate results usually require more time to retrieve. However, an efficient system can offer ultra-fast search with near-perfect accuracy, making vector databases an essential tool for handling large-scale data in machine learning, natural language processing, and recommendation systems.
